The XML DOM uses a tree-structure, also known as a node-tree, to view an XML document, i.e., each node can be accessed through the tree. We can also modify, delete, or create a new element through the tree. The set of nodes and their connections is what a node tree displays. Travelling across or looping through a node tree is called traversing.
Traversing the Node Tree:
We can need to loop an XML document in many situations, such as for extracting the value of each element, also known as “Traversing the node tree”.
Example: To loop through all the child nodes of <book> and to display their names and values:
Output:

Explanation:
In the above example, first, we are loading the XML string into xmlDoc to get the child nodes of the root element. Here, we will output the node name and the node value of the text node for each child node.
Browser Differences in DOM Parsing:
The W3C DOM specification is supported by all the modern browsers’ support but has some differences between browsers. One such difference is in the way each browser handles white-spaces and new lines.
DOM – White Spaces and New Lines:
A new line, or white space characters, are often present between nodes, especially at times when a document is being edited by a simple editor like Notepad.
Example:
ABC Unknown 2020 100.00
Explanation:
In the above example, a CR/LF or newline is present between each line and two spaces are present in front of each child node. The above document was edited by Notepad. Empty white-spaces, or newlines as text nodes, are not treated by Internet Explorer 9, however, other browsers do.
Example:
Output:
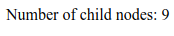
Explanation:
In the above example, the output is the number of child nodes the root element of note.xml has. For the same code, IE10 and later versions, and other browsers will output 9 child nodes, but IE9 and earlier versions will output 4 child nodes only.
PCDATA – Parsed Character Data:
The text data that will be parsed by the XML parser is also termed as Parsed Character Data (PCDATA). Usually, all the text in an XML document is parsed by the XML parsers. The text between the XML tags is also parsed if an XML element is parsed.
Example:
Hello World!
The reason for this is simple and that is because XML elements can contain other elements.
Example:
Tom Cruise
Here, two other elements i.e., first and last are present in the <name> element. The parser will thus break it up into sub-elements.
Tom Cruise
CDATA – (Unparsed) Character Data:
The text data that should not be parsed by the XML parser is also termed as CDATA or Character Data. In an XML element, the characters like “<” and “&” are illegal, because the parser interprets “<” as the start of a new element and “&” as the start of a character entity and thus generates an error. A lot of “<” or “&” characters are often included in JavaScript code or other texts. Thus we need to define the script code as CDATA to avoid errors. The parser ignores everything inside a CDATA section. Starting with “<![CDATA[“, a CDATA section ends with “]]>“. Thus, the string “]]>” can’t be included in a CDATA section and when used as the end of a CDATA section, it can’t contain spaces or line breaks. Also, XML does not allow Nested CDATA sections.
Example:
Explanation:
In the above example, the parser ignores everything inside the CDATA section.